The number of Internet users grows every day with constant progression. The more users around, the bigger load is laid down on servers that host web and mobile services. As a result, the technologies that ensured the serviceability of the system a year ago can appear to be obsolete nowadays. To stay tuned, a developer should always track some trends in quick-changing technologies. Nevertheless, they should apply sustainable methods tested with time and load to make their products stable.
With this article, we describe the weakest points of the development process of the architecture of a high-load PHP project. The conclusions are based on the practical experience we received after passing one challenging project. Apply our nontrivial tips to enhance your own process of architecture building.
To get closer to a point – The challenge we received
One day we got a task to develop a social media advertising platform with daily traffic enumerating approximately 35-40 million queries a day. This is a rather small number for a common project. Though, understanding the processing of advertisement purchase models and algorithms in social media was sufficient enough to give the mark “high-load” to this project.
Several advertising models (CPA, CPL, CPC, and CPM) were integrated into the project already. Our task was to scale up the platform – connect additional models, make a function of partnership with other networks, develop the connections network. The platform was active, but we had to track its performance as it failed regularly. Together with growing traffic, its uptime steadily declined. As a result, we had to make a platform that processes 900 million queries a day, which is rather a huge number. Under such conditions, the project greatly depends on the architecture proper arrangement.
To avoid failures in the future, we had to work through the idea thoroughly. The initial steps included: (a) figuring out the ways everything should work, (b) division the project into modules, (c making suggestions on how the modules should share their data. That all had to be done with the application of the best practice methods and technologies.
Note: Any point in this article has the same importance as the other ones. To develop an effective high-load project, it is essential to apply the maximal number of all recommendations. The integration of a module or the function with weak performance can influence the general productivity of the project. That will bring further losses to the business operating this product.
1 – Microservices and scaling calcualtion
One of the most fundamental points in the development of a high-loaded product is the separation of the project into modules. The more smoothly and independently these modules will operate, the more productive the system will be. The product will get a variety of advantages: improved stability in case of unserviceability of one of the modules and distribution of the load among all modules.
Calculation of the possibility of the project’s future scaling out should be performed at the moment of planning, but not deployment.
Why are these two points so important?
Imagine a seamless project where the service responsible for one of the payment methods had failed. The entire project’s proper serviceability is threatened under such conditions. But if this failure negatively influenced the service managing the data flow or the general operation of the database, that can become a real problem.
The architecture structure should ensure the failure fixes and further updates deploy in the shortest period without the creation of the snowball effect.
2 – Framework selection
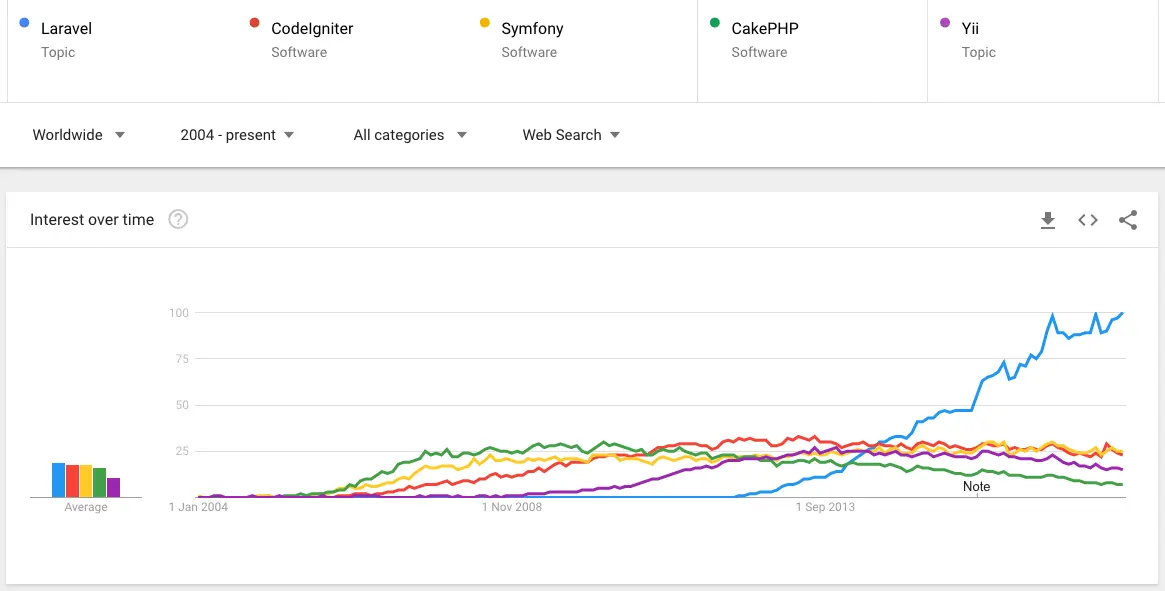
We had chosen Laravel as one of the most lightweight, though efficient frameworks. Its architecture helps to develop rather efficient projects. The level of productivity depends on several factors: the quality of the developers code, the chosen architecture of the application, coding methods, and patterns. Later in this article, we will describe more deeply these factors and their impact on product quality.
In addition, Laravel is becoming more popular according to the trends of recent years. The growing interest in this topic shows that developers trust this framework and prefer using it in their projects.
3 – Database selection
The database is one of the most productively weak, though integral points of architecture development. The non-proper selection of which can threaten data security along with the entire project serviceability.
Before the start of the development process, it is necessary to choose the appropriate Database Management System. Any DBMS has its peculiarities in operation and requires at least one strong-skilled person who will manage the base.
The core feature of any database is its operational speed. If we compare the types of databases according to their relativity, non-relational DBMS is always faster than a relational one. We can outline two basic reasons for such characteristics: (a) the number of relations between data pieces in tables and (b) optimization of non-relational bases as in-memory databases or storages.
So, what had we chosen for our project?
Redis Server + Percona MySQL Server
Why particularly this pack, and how is it possible to use them together?
The most significant advantage of Redis is that it can work as the cache server and persistent database storage. The more professionally Percona will be integrated and adjusted in this pack, the more efficient the entire project will be.
Find the ways Redis can be used as the persistent database storage and the perspective of its operation from the inside in the official tutorial.
Why Redis instead of identical NoSQL?
We selected Redis due to the variety of functions it can be used.
It is not just key-value storage, it is stacks, arrays, hash sets, intfloat-type storage, the mechanism of messages broadcasting, and dozens of other things that are useful for a future product.
When talking about Laravel as the leading framework we applied in the project, the most suitable library to work with Redis is predis/predis. Laravel can work with it without supplementary adjustments.
Install the library with a composer, and activate it by adding the following lines to .env file:
REDIS_CLIENT=predis REDIS_HOST=127.0.0.1 REDIS_PASSWORD=MyStrongPassword88LVL REDIS_PORT=6379
Note that Laravel works with Redis clusters, so there is no need to complicate things. All you need is to fill in the config/database.php file in the “Redis Databases” section. We will describe some great products to work with Redis clusters in the text below.
You can perform automatic caching of all queries from your models with expirable.
What should be stored in Redis?
As was mentioned before, the core parameter of any database is the speed of information packets transmission. There is one general recommendation to enhance data processing speed. The less often the relative database is used, the faster operation of the system will be. Though, it is impossible to avoid the use of the relative databases in real life. As an alternative, we recommend using the data from Redis as much as possible.
Redis stores all data in RAM that enables a rather high level of performance. It is possible to store in Redis not only “key-meaning” data but also totally proportional to the table data. For example, let’s save the object of the “User” type that is available in Laravel:
127.0.0.1:6379> HMSET users:2 id 2 name Admin email "admin@gmail.com" email_verified_at NULL password "BCRYPTED_PASS" OK 127.0.0.1:6379> HGETALL users:2 1) "id" 2) "2" 3) "name" 4) "Admin" 5) "email" 6) "admin@gmail.com" 7) "email_verified_at" 8) "NULL" 9) "password" 10) "BCRYPTED_PASS"
Consequently, we can get only the name of the needed user.
127.0.0.1:6379> HGET users:2 name "Admin"
Redis’s functionality is sufficient enough to copy the relativity of any database, and its efficiency is the reason to do so.
Instagram can be a well-known example of a high-load project with a non-relational database, as it uses NoSQL.
Unfortunately, Redis is not limitless in performance. Sooner or later there will be a situation when the performance of one server is not enough. The solution can be found in replication to 2 servers, 3 servers, 4… But this brings another problem – it is not always obvious how to work with servers from the application. twemproxy can become the solution to this situation in the form of proxy for Memcached and Redis servers. It is easily organized, and it works great.
Ok, and what about Percona, why do we apply it?
This is not the best option of DBMS to use, but if you compare common relational DBMSs similar to MariaDB, Percona has several advantages in the area of effectiveness.
Percona is operatively non-complicated, similarly to MariaDB. Percona has no differences in SQL syntax or any other place of interaction with the client.
Install Percona to the server, adjust it, and create the database. Simply perform these three steps to run your application.
Also note, if your application is done in several programming languages, probably you will have to install the libperconaserverclient20 packet.
There are so many additional recommendations on server adjustments that they can build a separate article. Though, even the steps described above can be enough to launch your database successfully.
The additional big bonus of Percona is the “Percona Toolkit” that can help you with analysis of the inquiries, tables, adjustments. Also, it is useful for quick changes introduction on a live server, dumps, reindex, and index creation without table blocking.
3.1 – Tables blocking
While working with a relative database, it is important not to block the table in any way, especially on a live server of a high loaded project. We had never tested this event in real life, though it is obvious that with such an amount of traffic one-second blocking can lead to enormous data loss. And if the queue includes too many pieces of data, their mass addition in the moment of unblocking can down the server for a short time.
RabbitMQ and similar queue servers with a limited number of parallel connections can save your database from downing.
3.2 – Replication
It is hard to imagine a high-load project that can survive with a single database located at one server without replication. That sounds like a dream and nightmare at the same time. With the growing number of queries, the number of data pieces grows proportionally. Sooner or later, the moment will come when the efficiency of the product would fail due to numerous SELECTINSERT queries.
You can split the database among the servers to avoid this. That ensures that the long term queries are divided among the servers and the overall delay of other queries is lowered.
3.3 – Direct INSERT
With the great amount of data to be recorded, numerous queries can be performed for too long. The speed of data recording is often limited with the readingrecording speed of your drive for two reasons: (a) during the insert moment all indexes in the table are reindexed, and (b) relative databases generally store their data on a hard drive.
As for the application part, the main recommendation is not to make inserts directly from API or WEB queries. It is preferable to work with a queue server. Luckily Laravel and mostly any other framework can work with queues. This is not even a recommendation but a warning – adding data directly from controllers can drop the database.
Find how to work with queues and tasks in Laravel in this article.
3.4 – Indexes
Proper index linking is an integral point for database efficiency. The availability of the required index will accelerate the search of the necessary line with the data. Though the availability of the non-required index will extend the time needed to record new data, as in the moment of insert, all data will be reindexed. On the stage of alpha-testing or even earlier, it is necessary to outline the columns with the most important and time spending queries. You can make this with “EXPLAIN” SQL directive.
For example, this is the screenshot with data selection from the conversion table. It has approximately 135 million lines with an active index. That is why the number of passed lines after sorting enumerated 7051.

Here we can see the reverse situation when there is no index in the table:
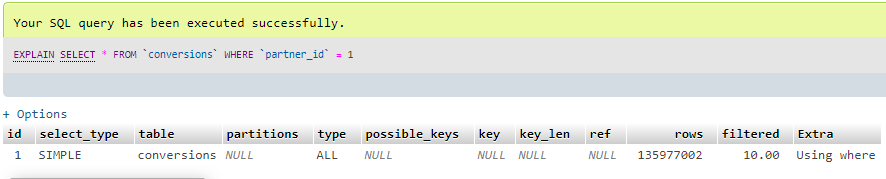
In the query without index, all 135 million lines were checked.
Now, let’s check the time needed to perform these two queries in real life. Here is the first example without the indexes:

And here is the identical query with indexes:

3.5 – INSERT DELAYED feature
This useful feature of SQL servers, in particular MySQL, is used very rarely in real cases. From the view of synthesis, this command is similar to the common INSERT but it allows adding necessary lines without server response. This can help in case of saving the logs data or other non-critical for the result of data insert items.
Unfortunately, INSERT DELAYED feature works only with ISAM and MyISAM engines and up to MySQL version 5.6.
4 – Balancing of queries
The possibilities of separation of application into modules should be always added from the very start of architecture planning. That will help to arrange the effective load splitting in the future.
DNS Round Robin is a widespread method of queries separation, though not so many people know about the way of queries organization according to countriescitiesproviders arrangement.
Usually, this method is used for back-end servers of desktop or mobile games. This approach allows to reduce the time of dispatch and receipt of packages – reduce ping. In our case from the example, when the advertising net receives traffic from numerous countries, it would be better to divide the load among the local servers of the client-country.
Most of the companies choose BIND9 as a DNS server. It is rather fast and easily adjustable. Moreover, it has specifically developed the GeoDNS module to sort the traffic according to geo-location.
Here is an example of a configuration made to organize queries balancing for appropriate backends from the particular countries of Europe.
view "west_europe" {
match-clients { country_AU; country_BE; country_GE; country_FR; country_GE; country_GB; };
recursion no;
zone "google.com" {
type master;
file "pri/google.west_europe.db";
};
};In addition, a great way to separate the queries – to state several IP addresses in DNS A record leading to different balance servers.
Here is the explanation: we had three servers instead of a single one to use for balancing. We stated in A record all three addresses of servers for the browser to choose them in a row. This succession created some kind of balancing. Unfortunately, the load was separated not evenly, though even such a non-perfect system is better than nothing.
5 – Application development analysis
The application will grow with time, resulting in new challenges with performance, the rapid growth of the database, and queries. Even when creating an ideal architecture, someday it would become non-suitable for the problems of the current day. This often happens due to the inability to forecast the directions of the product’s further development. Constant analysis can show the weak areas that require changes to guarantee the application does not lose its pace.
We tried several products for system monitoring, but our top pick is Percona Monitoring and Management. Here is an example of cluster analysis performed with this tool.
Nevertheless, we recommend the following tools for Laravel application monitoring: blackfire.io, inspector.dev, and sentry.io.
Always mind soft part to stay effective
Unfortunately, it often happens that the companies or startups observing the fast growth of their product try to make its architecture ideal. As a result, they introduce numerous mistakes and get unnecessary problems. It is unpredictable in what way the product will grow further, and the technologies used to build an “ideal” architecture can become unnecessary and overburdened eventually.
Do not try to make the architecture ideal from the project start. You should clearly understand the way the project is going to develop further, regardless the technologies applied PHP or .NET .
Imagine the situation: yesterday you have built the ideal architecture. Today you understand that it is necessary to rework some parts or functions of your application to make it effective. Unfortunately, the immediate introduction of necessary changes often appears to be impossible. Such rectifications can take too much time, or you should develop the next functions without coming back to fixes of the actual code.
The inability to introduce immediate changes can be an additional reason to use the microservice architecture. It enables the separation of application to detached services or modules. You can rewrite some functions in one of the modules, even in a low-level programming language, and that action would not affect other modules.
With this conclusion, we come back to the first point of this article. This affirms the statement that all these points are essential for a successful PHP architecture development and the way they are interrelated and used in practice.
 206
206









")